Our perspective of the Best Sound
Our philosophy is that a great sound system should faithfully reproduce the original sonic characteristics as perceived by the human auditory system. This may seem simple, but it is much more challenging than it appears.
Imagine a perfect microphone with a flat frequency response from 20Hz to 20kHz (the human hearing range) that can capture every sound with accurate dynamic levels. Paired with a perfect speaker that has an identical flat response, the inputs would be identical to the outputs - what you hear from the source is exactly what you get from the speaker. This represents the definition of the best possible sound quality.
Numerous reputable studies have shown that a flat frequency response is a key criterion for delivering the most enjoyable sonic experience to listeners. Loudspeaker design and manufacturing prioritize achieving this flat response. However, when we measure the system in a real-world listening room, it is nearly impossible to obtain a truly flat response.
The published frequency response specifications of speakers are typically measured on the "acoustic-center axis" (in-phase plane) in an anechoic chamber (without reflections). This is done to eliminate the effects of the surrounding environment and off-axis signal interference. But once the sound interacts with reflective surfaces in a real room, the measurement becomes "contaminated." Since we cannot control the user's listening environment, we cannot standardize a single target response - each room has unique acoustic characteristics.
These environmental factors significantly alter the direct sound from the speaker before it reaches the listener's ears. There are simply too many variables to track and account for, making it almost impossible to maintain the original sound fidelity.
No matter how much you invest in the sound system or room acoustics, the sound quality will be compromised to some degree, preventing the system from reaching its full potential. It's like having too many bright lights spotlighting a picture, and we need to reverse-engineer the painting to retrieve the true, original colors.
We understand that objectively measuring sound quality is challenging, as auditory perception is highly subjective. People have lost faith in the calibration process because, when not done correctly, it can make the sound quality worse than leaving the system uncalibrated.
After over 20 years of studying the science behind these sound alterations, we have developed the knowledge and specialized techniques to align measurement data with human perception. We call this the "Timbre Chart Tuning” method, and we are excited to share this outstanding sound quality solution with the world.
Our comprehensive approach to achieving the best sound quality focuses on three main factors:
- Propagation behavior differences of sound sources
- Reflections mixed with direct sound
- Spectral/spatial shifts due to speaker directivity and throw distance
To address these factors, we employ four key strategies:
- Spectral balance
- Phase consistency
- Sonic (stereo) image reconstruction
- Coverage optimization
TIMBRE THEORY (COLOR THEORY IN SOUND)

Timbre Theory (Color Theory in sound)
One day, I watched my 3-year-old daughter playing with clay, mixing and rolling different colors together into a small planet. When I asked her what her favorite color was, she would always say "rainbow." I think this is because rainbows display almost all the colors we can see in the visible spectrum, giving us the fullest color contrast and the most beautiful phenomenon that most people can agree on.
The same principle can be applied to audio. To reproduce the highest sound quality for listeners, a good sound system must not only be able to reproduce all the frequencies we can hear across the audible spectrum, but it must also deliver those frequencies accurately in terms of loudness level and phase relationship. The question is, how do we determine what "accurate" means for human perception?
Off-sweet-spot response
It's not uncommon to find speakers in the market that have an excellent frequency response specification. However, people often complain that these "good response" speakers don't actually deliver good sound quality in real-world listening scenarios.
The reason for this is that the ideal, flat frequency response is typically only achieved within a very narrow "sweet spot" - a small, specific listening position. The published frequency response measurements are usually taken at 1-2 meters on the speaker's acoustic axis, in an anechoic chamber. But manufacturers cannot customize each speaker to fit the unique listening angles and distances in every user's environment.
That's why speakers require calibration to perform well in different environments; they need specialized tuning to deliver their full potential outside of the controlled anechoic conditions. The flat frequency response specification alone does not guarantee good sound quality when the speaker is placed in a real-world listening room with reflections and other acoustic variables.
Why the Off-sweet-spot response is important too?
In a real-world listening environment, we don't just hear the direct sound coming straight from the speakers. We also hear the reflected sound bouncing off the surfaces in the room. The direct sound can be manipulated, but the reflected sound is largely out of our control.
The direct and reflected sounds become mixed and altered together before reaching our eardrums. The speakers act like the strings of a guitar, while the room functions as the guitar's resonant body, becoming an integral part of the overall sound.
What's interesting is that our brains can differentiate between the direct and reflected sounds to some degree, but not fully. It's hard to determine exactly how much of each component is mixed in our perception, and to what extent our hearing system can separate them.
The more important question becomes: Can we control the final combined sound by manipulating the input signals before they mix in the room? In other words, can we pre-compensate for the acoustic interactions to achieve the desired overall sound?
What makes the Off-sweet-spot response different at the first place?
The nature of the sound source itself is a key factor that causes sound propagation to behave differently at various angles, distances, and after reflections. The physical size of the sound source means that the frequencies in the spectrum have their own distinct directivity patterns and intensity attenuation rates.
Furthermore, the arrangement or positioning of multiple drivers within a loudspeaker, as well as the geometrically unstable reflections in the room, make these propagation behaviors even more complicated and unpredictable, especially in the crossover frequency ranges where the drivers are transitioning.
It is simply impossible for us to track and account for all of these complex interactions happening in a real-world listening environment. The factors influencing sound propagation are too numerous and difficult to fully predict or control.
RGB Spot Lights Analogy (See pic)
Let's use a visual analogy to illustrate the audio challenges we're addressing. Imagine there are three spotlights of different colors (red, green, and blue) shining on a projection screen in a room. These spotlights represent the individual drivers (woofer, midrange, tweeter) in a speaker system, and the screen represents the listening area.
Each light has its own inherent beam angle, just as audio frequencies have different directivity patterns. To emit a perfect white color at the central "sweet spot" on the screen, the intensities of these three lights must be perfectly balanced. This is akin to achieving the ideal spectral balance in the on-axis listening position.
However, if we look at the outer edges of the spot (off-axis), we start to see color distortion, fading into yellow, and ultimately turning red. This demonstrates why it's so critical to listen at the acoustic center of the speaker, where the perfect spectral balance occurs.
Now, let's make the situation worse. Imagine the room interior is no longer black, but instead painted in various random colors, mostly in red (representing no low-frequency absorption). These colored surfaces cause the light rays to reflect back to the screen (the listening area).
As a result, we no longer get the perfect white color at the central aiming point on the screen, and the colors shift elsewhere. In audio terms, this is where we need to use equalizers and filters to rebalance the frequency responses and retrieve the desired, accurate sound.
Reflections
In the visual analogy, it's relatively easy to paint the room black to absorb all the reflected light. Unfortunately, in the audio realm, it is much more challenging to absorb all the sound energy, especially the low frequencies, even in professional studio environments.
The low energy and narrow directivity of high frequencies make them less problematic to manage. However, the high power and omnidirectional nature of low frequencies make them extremely difficult to control. These low frequencies will continue bouncing around the room without much ability to contain them.
Linear Phase
Many people claim that we cannot perceive phase differences in sound. This statement is only true when the phase is already non-linear to begin with. Unless the speaker drivers are coaxial, the sounds from multiple drivers can only be in-phase at a very thin, specific listening plane - the acoustic center.
Off this central plane, the travel time of sounds from the different drivers to the listener's ears will be different. Factoring in the drivers' directivity patterns and room reflections, you end up with a directivity mismatch, which causes issues in the frequency response both on-axis and off-axis. At this point, the phase response is no longer linear and has become randomized. This results in a sound that has an electrically "reverberated" quality.
That's why when you play back a voice recording through a typical speaker system, it often doesn't sound like a real person speaking in front of you. The spatial cues and phase coherence are lost. The "auditory proximity" is absent.
Auditory Proximity
It's difficult to convey to people what good sound quality is without giving them the opportunity for direct A/B comparisons. The concept of "auditory proximity" is not widely discussed in the audio industry, but we believe it is closely tied to sound quality.
As coaxial or linear-phase speaker designs become more popular, people may start to appreciate the importance of this feature, especially as the current trend towards immersive audio requires such phase coherence. In our opinion, achieving this linear phase response, like that of the original raw sound source, is crucial for recreating a sense of auditory proximity.
The human ear detects this auditory proximity through the phase coherence of upper harmonics in the direct sound, which are randomized by early reflections. Preserving the harmonic phase is an essential element of reproducing realistic, natural-sounding audio.
Timbre Chart TUNING METHOD
Color Chart in Audio
If the primary sound quality issue with an audio reproduction system is the inconsistent frequency response across different listening environments with varying reverberation patterns, then maintaining a flat frequency response (FR) across all components in the signal chain would be the right approach. However, this FR maintenance must be relative to our human hearing, not just the analysis equipment, as the measurement tools do not perfectly align with our auditory perception.
Using our auditory system to flatten the responses is the key!
The first thing we need to identify is our individual frontal hearing response; it is definitely not flat, and it varies to some degree between people, much like fingerprints. These frontal and non-frontal responses also change depending on the sound direction.
Fortunately, we do not need to tune the system to match our individual ears; we are simply aiming to flatten the sound as it would naturally be in an anechoic (non-reflective) environment. We are utilizing our hearing mechanism to determine what the anechoic flat responses should sound like. We just need to focus the frequency domain analysis on our auditory system.
This approach is similar to color calibration for display screens. There are clever techniques that simplify the process for users without requiring deep color management knowledge. The idea is to provide a set of graphic color/brightness charts and simple instructions for users to create an accurate profile for their own displays.
Our Timbre Chart Tuning method takes a similar approach in audio. We have created a set of test tones designated for our well-trained engineers' frontal hearing. It acts like a personalized "color chart" in audio, allowing us to identify the true relative levels of each frequency band. Combined with other deep measurement tools, like specific time-windowed dual-FFT techniques, we can then recreate the best frequency response that the system is designed to deliver.

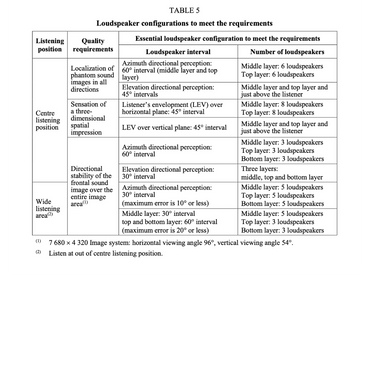
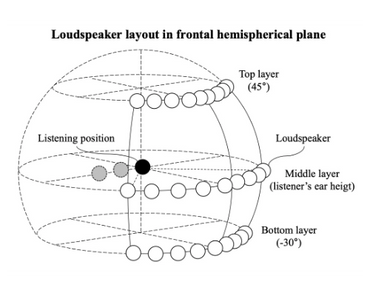
(Ref. ITU-R BS.2159-7 )